Data Pipelines
Schema-agnostic, dynamic configuration-based approach to data delivery at scale. No service disruption to any changes
A data pipeline connects the data source to a target store/system. The data source generates the data and posts it to the Braineous ingestion system via the Braineous Data Ingestion Java SDK. Braineous data pipeline engine supports multiple data sources and multiple target systems that can be associated with a single pipe. In turn it supports as many pipes that maybe necessary for the applications in question at scale.
Braineous transforms any data-format. (XML,CSV, or JSON) into JSON for it's processor. Once JSON a simple Object Graph and uses configured JSONPATH-expressions to produce data for the target system and delivers it to desired data-format. Completely dynamic. Just change the pipe configuration and roll.
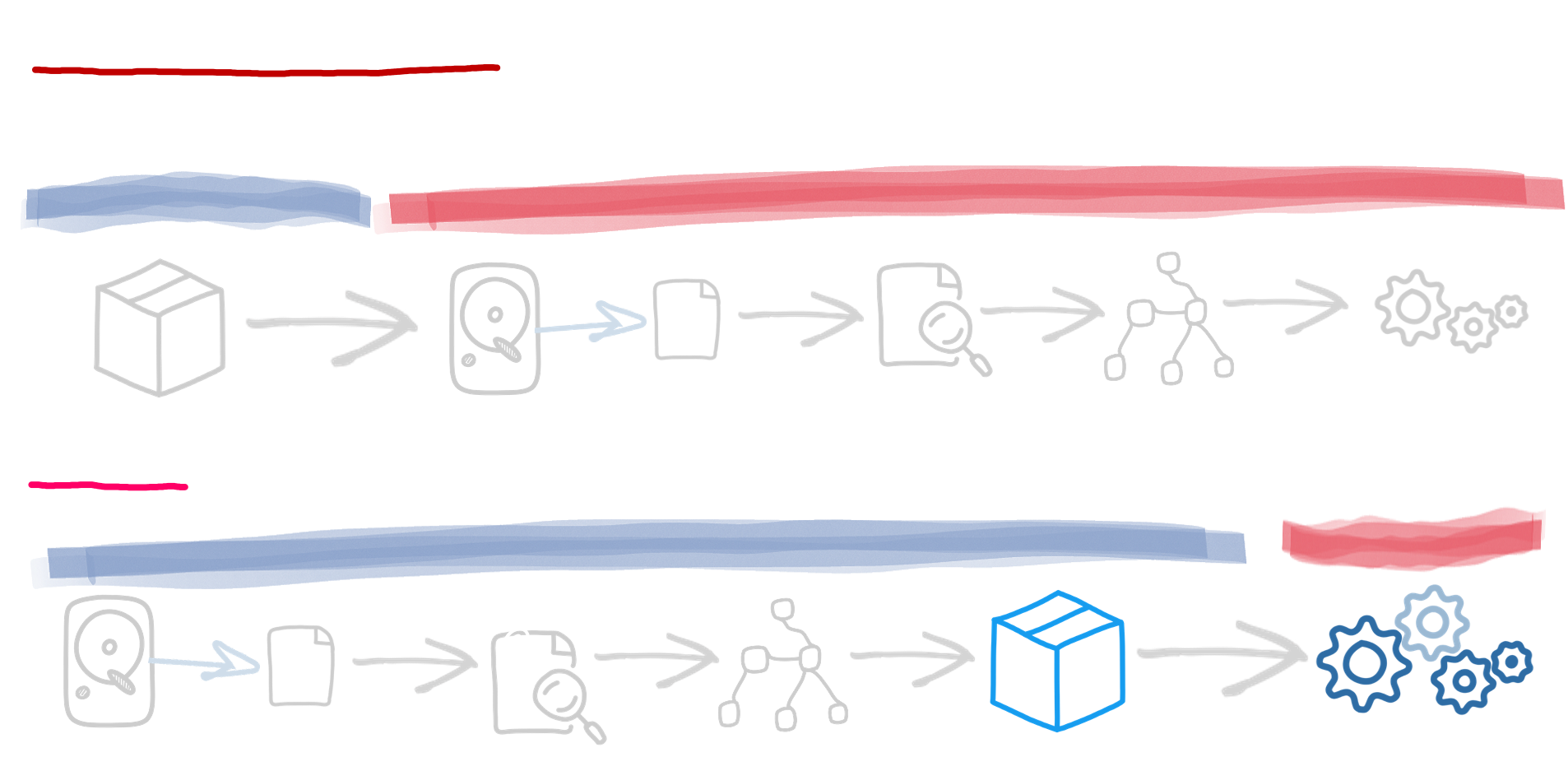
Data Ingestion
The Data Ingestion process starts by sending data to the BRAINEOUS Data Ingestion endpoint. It is processed asynchronously as the data moves through its pipe through an Apache Kafka Topic and an Apache Flink Stream Processor
Each ingestion goes through an ordered process of phases which are
Scale
Scale is elusive yet attainable. A single Braineous pipeline can be associated with thousands of target staging stores, all evolving over time. And thousands of pipelines can be added with no disruption for a single tenant. Braineous is designed to not have the concept of downtime. Evolve your network at runtime, not static time.
Accuracy
Every record ingested by Braineous is stored on a clustered Kafka log and also in the Data Lake. It keeps two sources of truth.
Data Elasticity
Braineous bridges the unstructured dataset to the structured dataset on the fly. Your Data Lake evolves with the dataset. Analytics and Machine Learning need structured queries for training the AI model. Braineous bridges two Worlds on the fly. Downtime is a time that is entirely unacceptable for Braineous.