High Scale Data Ingestion
Continuously ingest and transform data streams at scale.
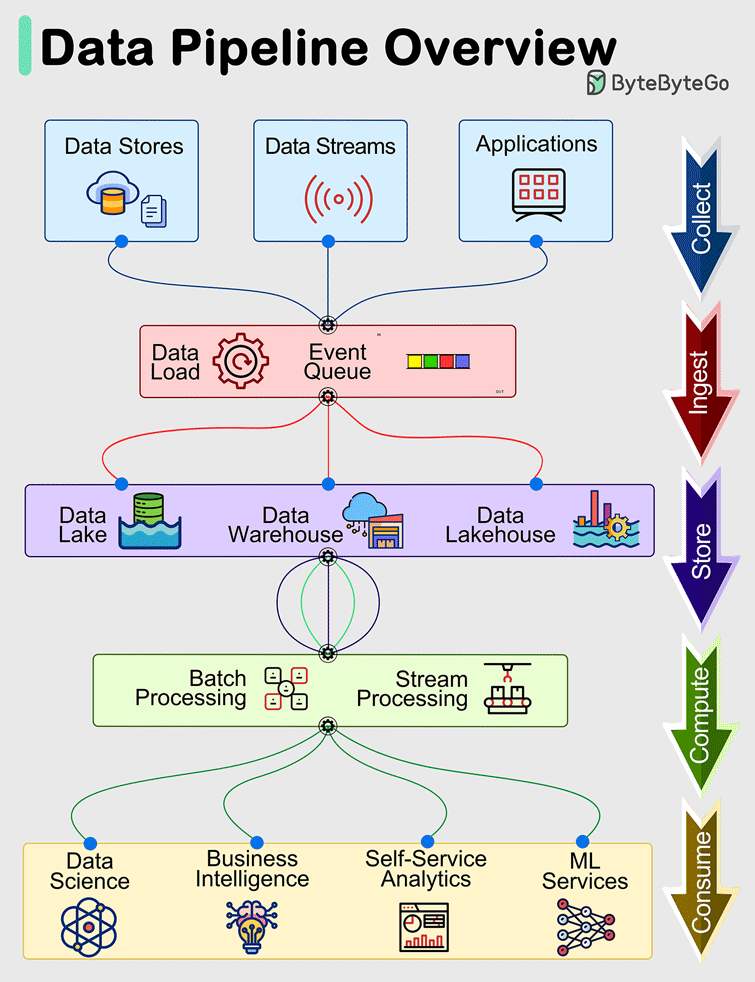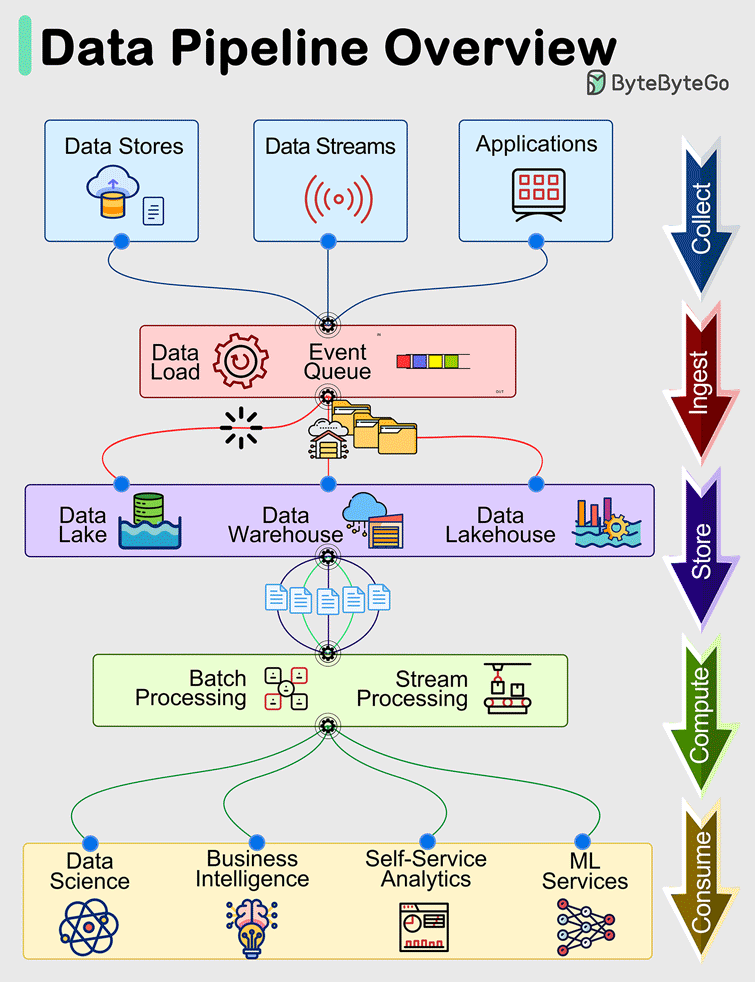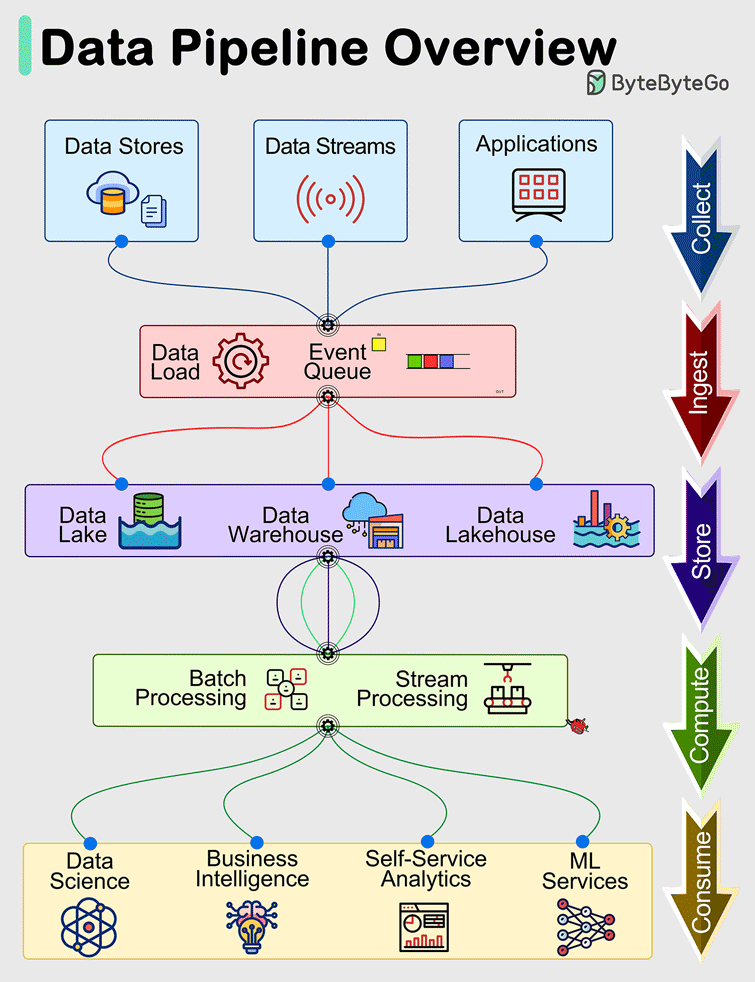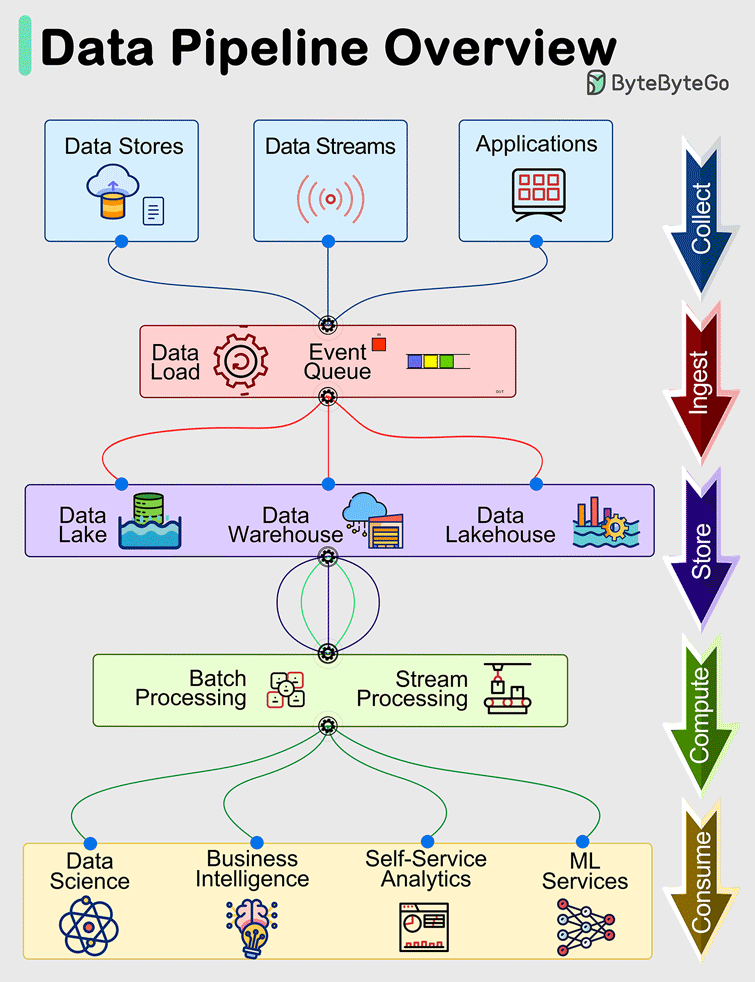
What is data ingestion?
Data ingestion is the process of acquiring, validating, transforming, cleaning, and storing data from arbitrary data sources for downstream use by applications.
It involves moving data from where it’s generated – whether databases, mobile devices, IoT sensors, etc. – into a target system where it can be used by the application. Some usecases: Eliminating data silos in an Enterprise Sharing data with business partners Staging live data for data scientists for training machine learning models Enabling business intelligence tools to produce actionable insights
What is high-scale data ingestion?
Conceptually data ingestion involves a source system the produces data and a target system that uses that data. In the case of high-scale data ingestion, the data is generated by systems that capture data from their environment in real-time such as mobile devices, sensors, operations such as flights, navigation, etc. The volume and velocity of this data which is considered events in the Braineous ingestion system, is very high.
Batch-based data ingestion
There are two primary approaches to data ingestion: batch and streaming. Batch ingestion pulls data from sources on a scheduled basis, such as once a day. This works well for high-latency analytics using historical data. Streaming ingestion consumes data in real-time as it’s generated. This enables use cases requiring fresh data like operational monitoring. Choosing between batch or streaming depends on how quickly the insights need to be available. Streaming provides faster data but requires more complex infrastructure to ensure reliability at scale.
On-Time data
In our hypothetical example, the mobile game is the main revenue generator for the company. Stakeholders need to see key metrics – e.g., new signups by marketing campaign – in near-real time, since allowing an issue to persist for days could cost many thousands of dollars in lost revenue. Meeting these requirements with traditional batch processing methods is difficult and costly. In order to make the data available for analysis in a reasonably-short timeframe, it needs to be ingested as a stream. At the same time, data needs to be correctly joined and aggregated so that the person viewing the Daily Signups dashboard sees accurate data. This becomes more complex the closer to real time the data needs to be (<1 hour is much simpler than <1 minute).
Ordering
In our example, we’re collecting millions of events from thousands of devices. Some of these events will arrive late, for example due to the device losing internet connection. However, we want our reports to reflect reality, which means ordering the records according to the time the event occurred, rather than the time the data was ingested. Databases solve this problem through serialization – but in distributed systems, moving every event through a database introduces latency constraints and performance bottlenecks. And while Apache Kafka guarantees ordering within a single partition, you’ll still need to ensure that all the relevant events end up in the same partition – which is constrained by the volume of data it can store.
Data consistency
We need to ingest, process, and store each data record once and only once – meaning no duplicate events and no data loss, even in the case of failures or retries. In our mobile gaming scenario, doing this at scale will require coordinating efforts between multiple distributed systems while managing the complexities of network communication, processing, and storage. This is a streaming-specific issue and thus won’t be addressed by most traditional data ingestion tools. When the pipeline tool can’t verify exactly once-semantics, data engineers must rely on a combination of frameworks and technologies to make it work in different pipelines. Going down this route, you’d also need to orchestrate custom logic to manage state, track progress, and handle retries or failures. The process is as time-consuming and error prone as you’d expect.